
MapReduce关系代数运算——自然连接
关系沿用之前的R。
创建两个文件
| id | name | sex | age |
|---|---|---|---|
| 1 | Amy | female | 18 |
| 2 | Tom | male | 19 |
| 3 | Sam | male | 21 |
| 4 | John | male | 19 |
| 5 | Lily | female | 21 |
| 6 | Rose | female | 20 |
| id | class | grade |
|---|---|---|
| 1 | Math | 89 |
| 2 | Math | 75 |
| 4 | English | 85 |
| 3 | English | 95 |
| 5 | Math | 91 |
| 5 | English | 88 |
| 6 | Math | 78 |
| 6 | English | 99 |
| 2 | English | 80 |
MapReduce程序设计
- NaturalJoinMap
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
public class NaturalJoinMap extends Mapper<LongWritable, Text, IntWritable, Text> {
private String fileName = "";
private Text val = new Text();
private IntWritable stuKey = new IntWritable();
protected void setup(Context context) throws java.io.IOException, InterruptedException {
FileSplit fileSplit = (FileSplit) context.getInputSplit();
fileName = fileSplit.getPath().getName();
};
protected void map(LongWritable key, Text value, Context context) throws java.io.IOException, InterruptedException {
String[] arr = value.toString().split(" ");
stuKey.set(Integer.parseInt(arr[0]));
val.set(fileName + " " + value.toString());
context.write(stuKey, val);
};
}
- NaturalJoinReduce
import java.util.ArrayList;
import java.util.List;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class NaturalJoinReduce extends Reducer<IntWritable, Text, Text, NullWritable> {
private Text student = new Text();
private Text value = new Text();
protected void reduce(IntWritable key, Iterable<Text> values, Context context) throws java.io.IOException, InterruptedException {
List<String> grades = new ArrayList<String>();
for (Text val : values) {
if (val.toString().contains("student")) {
student.set(studentStr(val.toString()));
} else {
grades.add(gradeStr(val.toString()));
}
}
for (String grade : grades) {
value.set(student.toString() + grade);
context.write(value, NullWritable.get());
}
};
private String studentStr(String line) {
String[] arr = line.split(" ");
StringBuilder str = new StringBuilder();
for (int i = 1; i < arr.length; i++) {
str.append(arr[i] + " ");
}
return str.toString();
}
private String gradeStr(String line) {
String[] arr = line.split(" ");
StringBuilder str = new StringBuilder();
for (int i = 2; i < arr.length; i++) {
str.append(arr[i] + " ");
}
return str.toString();
}
}
- NaturalJoin
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class NaturalJoin {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
if (args == null || args.length != 2) {
throw new RuntimeException("请输入输入路径、输出路径");
}
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJobName("NaturalJoin");
job.setJarByClass(NaturalJoin.class);
job.setMapperClass(NaturalJoinMap.class);
job.setMapOutputKeyClass(IntWritable.class);
job.setMapOutputValueClass(Text.class);
job.setReducerClass(NaturalJoinReduce.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(NullWritable.class);
FileInputFormat.addInputPaths(job, args[0]);
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
运行
像之前的WordCount一样将代码打包出来,生成NaturalJoin .jar文件:
hadoop jar NaturalJoin .jar /input /output relationB
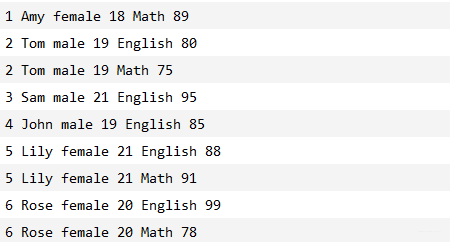
输出结果:
欢迎查看我的CSDN博客:Welcome To Ryan’s Home

|

|

|