
MapReduce关系代数运算
常见的MapReduce关系代数运算有:选择、投影、并、交、差以及自然连接操作等,本文将介绍选择运算。后续博文介绍其他运算。
关系R
|id|name|age|grade| | —— | —— | —— | —- | | 1 | 张小雅 | 20|91| | 2 | 何芳 | 18|87| | 3 | 李婷 | 21|82| | 4 | 孙强 | 20|95|
将关系R储存再R.txt中,上传到hdfs的/input目录下
MapReduce程序设计
- StudentR
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.WritableComparable;
public class StudentR implements WritableComparable<StudentR> {
private int id;
private String name;
private int age;
private int grade;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public int getGrade() {
return grade;
}
public void setGrade(int grade) {
this.grade = grade;
}
@Override
public String toString() {
return "StudentR [id=" + id + ", name=" + name + ", age=" + age + ", grade=" + grade + "]";
}
public StudentR(String line){
String[] value = line.split(" ");
this.setId(Integer.parseInt(value[0]));
this.setName(value[1]);
this.setAge(Integer.parseInt(value[2]));
this.setGrade(Integer.parseInt(value[3]));
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + age;
result = prime * result + grade;
result = prime * result + id;
result = prime * result + ((name == null) ? 0 : name.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
StudentR other = (StudentR) obj;
if (age != other.age)
return false;
if (grade != other.grade)
return false;
if (id != other.id)
return false;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
return true;
}
public boolean isCondition(int col, String value){
if(col == 0 && Integer.parseInt(value) == this.id)
return true;
else if(col == 1 && name.equals(value))
return true;
else if(col ==2 )
{
if(Integer.parseInt(value)<age)
return true;
else
return false;
}
else if(col ==3 && Double.parseDouble(value) == this.grade)
return true;
else
return false;
}
public void write(DataOutput out) throws IOException {
out.writeInt(id);
out.writeUTF(name);
out.writeInt(age);
out.writeDouble(grade);
}
public void readFields(DataInput in) throws IOException {
id = in.readInt();
name = in.readUTF();
age = in.readInt();
grade = in.readInt();
}
public String getValueExcept(int col){
switch(col){
case 0: return name + "," + String.valueOf(age) + "," + String.valueOf(grade);
case 1: return String.valueOf(id) + "," + String.valueOf(age) + "," + String.valueOf(grade);
case 2: return String.valueOf(id) + "," + name + "," + String.valueOf(grade);
case 3: return String.valueOf(id) + "," + name + "," + String.valueOf(age);
default: return null;
}
}
public int compareTo(StudentR o) {
if(id == o.getId() && name.equals(o.getName())&& age == o.getAge() && grade == o.getGrade())
return 0;
else if(id < o.getId())
return -1;
else
return 1;
}
}
- Selection
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import java.io.IOException;
public class Selection {
public static class SelectionMap extends Mapper<LongWritable, Text, StudentR, NullWritable>{
private int id;
private String value;
@Override
protected void setup(Context context) throws IOException, InterruptedException {
id = context.getConfiguration().getInt("col", 0);
value = context.getConfiguration().get("value");
}
@Override
protected void map(LongWritable key, Text line, Context context) throws IOException, InterruptedException {
StudentR record = new StudentR(line.toString());
if(record.isCondition(id, value))
context.write(record, NullWritable.get());
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
//selectionJob.setJobName("selectionJob");
conf.setInt("col", Integer.parseInt(args[2]));
conf.set("value", args[3]);
Job selectionJob = Job.getInstance(conf, "selectionJob");
selectionJob.setJarByClass(Selection.class);
selectionJob.setMapperClass(SelectionMap.class);
selectionJob.setMapOutputKeyClass(StudentR.class);
selectionJob.setMapOutputKeyClass(NullWritable.class);
selectionJob.setNumReduceTasks(0);
selectionJob.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.addInputPath(selectionJob, new Path(args[0]));
FileOutputFormat.setOutputPath(selectionJob, new Path(args[1]));
selectionJob.waitForCompletion(true);
System.out.println("Finished!");
}
}
运行
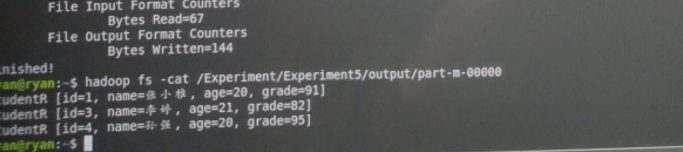
像之前的WordCount一样将代码打包出来,生成Selection.jar文件,但是在终端运行的时候,需要注意的是不只是输入两个路径,而应该输入选择的条件。如本例中,我们要选择出所有大于19岁的学生信息,则应该选定第三列Age字段,以及对Age字段设定的条件:
hadoop jar Selection.jar /input /output 2 19
查看输出结果:
欢迎查看我的CSDN博客:Welcome To Ryan’s Home

|

|

|