
一、实验目的
熟悉HDFS的命令行操作和Java访问HDFS的方法
二、实验平台
- 操作系统:Linux
- Hadoop版本:2.7.1。
- Maven
三、实验步骤
1. 下载Maven
2. 更改Maven本地源:新建Settings.xml文件,复制下面的内容
<settings xmlns="http://maven.apache.org/SETTINGS/1.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/SETTINGS/1.0.0
http://maven.apache.org/xsd/settings-1.0.0.xsd">
<localRepository/>
<interactiveMode/>
<usePluginRegistry/>
<offline/>
<pluginGroups/>
<servers/>
<mirrors>
<mirror>
<id>aliyunmaven</id>
<mirrorOf>central</mirrorOf>
<name>aliyun maven</name>
<url>https://maven.aliyun.com/repository/public </url>
</mirror>
</mirrors>
<proxies/>
<profiles/>
<activeProfiles/>
</settings>
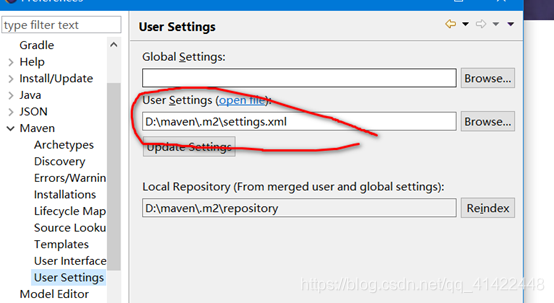
在Eclipse菜单栏依次选择Windows->Preferences->Maven->User Settings中,选择上一步中新建的Settings.xml文件
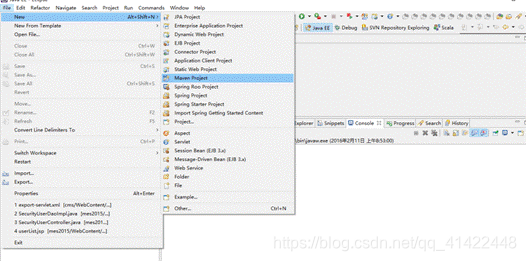
3. 创建Maven Project
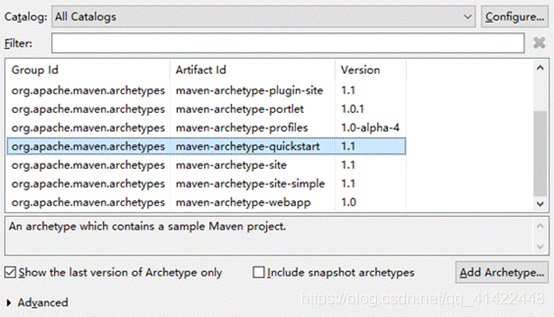
 选择 Maven-archetype-quickstart 选项
选择 Maven-archetype-quickstart 选项
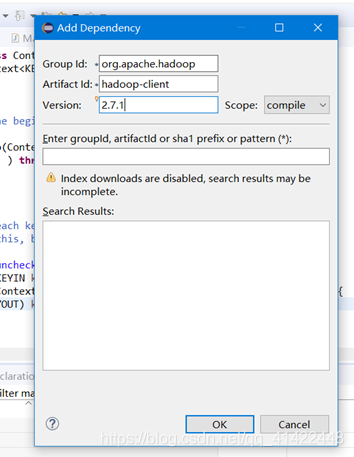
4. 添加Maven依赖项。右键项目依次选择Maven—>Add Dependency,输入Hadoop-client依赖
5. 编写WordCount程序
-
创建一个txt文件(单词之间用空格” “隔开)——WordCount所读取的文件
-
WordCountMapper
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 将文本内容先转换成String
String line = value.toString();
// 2根据空格将这一行切分成单词
String[] words = line.split(" ");
// 将单词输出为<单词,1>
for(String word:words){
// 将单词作为key,将次数1作为value,以便于后续的数据分发,可以根据单词分发,以便于相同单词会到相同的reducetask中
context.write(new Text(word), new IntWritable(1));
}
}
}
- WordCountReducer
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WordCountReduce extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int count = 0;
// 汇总各个key的个数
for(IntWritable value:values){
count +=value.get();
}
// 输出特定key的总次数
context.write(key, new IntWritable(count));
}
}
- WordCount
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static void main(String[] args) throws Exception {
//获取配置信息,或者job对象实例
Configuration configuration = new Configuration();
//配置提交到yarn上运行,windows和Linux变量不一致
// configuration.set("mapreduce.framework.name", "yarn");
// configuration.set("yarn.resourcemanager.hostname", "node22");
Job job = Job.getInstance(configuration);
job.setJarByClass(WordCount.class);
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReduce.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 指定job的输入原始文件所在目录
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 将job中配置的相关参数,以及job所用的java类所在的jar包, 提交给yarn去运行
// job.submit();
boolean result = job.waitForCompletion(true);
System.exit(result?0:1);
}
}
6. 提交到分布式 系统中与运行
- 先启动Hadoop
cd /usr/local/hadoop
./sbin/start-dfs.sh
- 再把新建的文件wordcount.txt上传到hdfs上:
./bin/hadoop fs -put -f ./wordcount.txt /input
- 打包WordCount代码,生成一个jar包,名为WordCount,选定主类为WordCount,保存在/usr/local/hadoop中:
- 运行jar文件:
hadoop jar /usr/local/hadoop/WordCount.jar /input /output
- 查看与与运行结果:
hadoop fs -ls /output
- 查看输出结果
hadoop fs -cat /output/part-r-00000
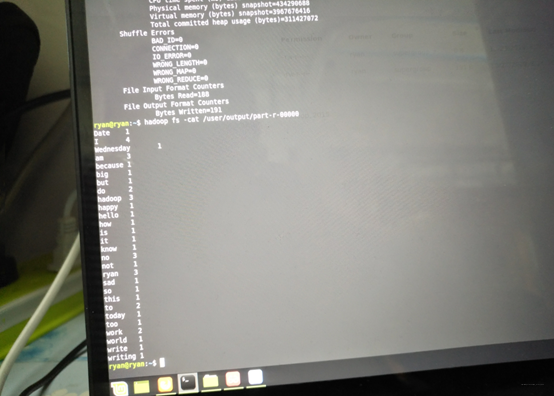
欢迎查看我的CSDN博客:Welcome To Ryan’s Home

|

|

|